
by Lorenzo Schiavina
EDOR Metodi Quantitativi
When I was a professor of Operation Research at the Faculty of Mathematics at the Catholic University of Brescia, I was lucky enough to contact Lofti Zadeh who was going to develop fuzzy logic and I was impressed by his work.
Subsequently I deepened the topic by reading the excellent book by Bart Kosko, Fuzzy Thinking, and I began to get interested into the approach and to convince myself that this technology could certainly be an extension of the models that I was used to implement.
As I have been dealing with computer science for more than 20 years and I was familiar with all the languages and computers of the time and I was lucky enough to be the first in Italy to know Smalltalk, I presented to the ESUG (European Smalltalk User Group), held in Brescia at my University, plans for an extension of Smalltalk classes (FuzzyWorld) that would be able to deal with fuzzy logic.









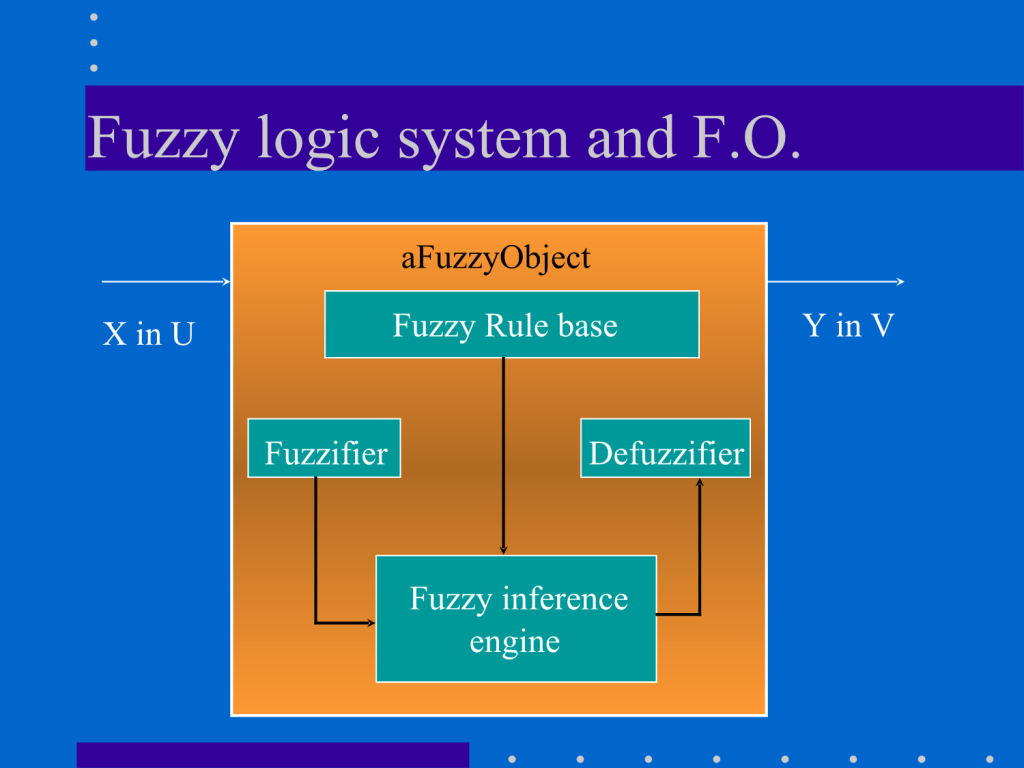





The first applications that I tried to develop convinced me that the tool offered absolutely unique possibilities and therefore I deepened my research thanks to two exceptional books.
The two books are:
- Fuzzy Systems Design Principles – by Riza C. Berkan and Sheldon L. Trubatch – ed. IEEE Press
- Adaptive Fuzzy Systems and Control – by Li-Xin Wang – ed. Prentice Hall
I was fortunate to develop an application for a premier league athletic soccer trainer and the result was excellent: for 3 years in a row, this trainer (moreover of non-top teams) was among those who had the least injuries; his testimony on my contribution was fundamental.
Since then, I have made fuzzy applications in the most diverse fields, integrating fuzzy logic with optimizations through genetic algorithms.






























Fuzzy logic is a tool that has been proven useful in dealing with and solving very complex problems; among these, forecasting problems are certainly to be included.
Since in the beginning of my activity I have had the opportunity to deal with investment problems, it seemed very interesting to do an experiment using this type of approach; the application was named FuzzyStock.
I therefore identified (in a completely random way) a stock listed on the stock exchange to verify the results that the use of this (discussed) computer technology could offer me.
The following pages show the data collected and their characteristics:

Synthesis window of the S&P title data used for the experiment
The input information of the experimentation is reported in the 3 areas:
• Title (S&P)
o Number of available data (682)
o Date of training surveys (02/01/01 to 24/09/03)
o Size of training data (598)
• Processing specifications
This is the fundamental point of the model: the training algorithm (a moving average implemented in fuzzy logic) which was the heart of the system, was applied to data from 1 to 598; the block (i.e. the fundamental training unit) was 9 data, starting with the first available data.
From the experience of analyzing the structure of the first 598 data, the algorithm had to “learn” how to move to evaluate the data from 599 to 682 and demonstrate whether it had “understood” or not how to make predictions; the time interval of the forecast ranged from 28/05/03 to 24/09/03 and the knowledge deriving from the analysis of data from 1 to 598 was applied to this interval
• Strategy specifications (demonstration not included)
The strategy specifications identified the elements for simulating the model’s performance (that was not fuzzy oriented):
Buying filter: percentage of growth in the price of the security to make a purchase
Selling filter: percentage of decrease in the price of the security to make a sale
Stop loss filter: percentage of error to decide the abandonment of the chosen strategy (purchase or sale)
Void selling filter: percentage of variation for short selling
Wrong forecasting filter: error percentage for changing strategy (purchase or sale)
The execution of training time of the model is about 6 seconds, after which the result of the forecast is presented:
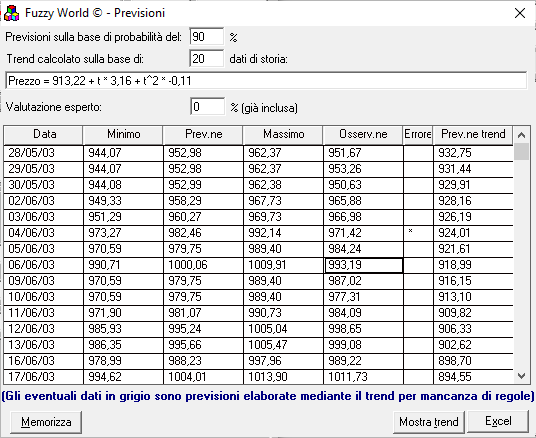
The result shows both the value of the fuzzy model and the “traditional” one of the trend (the old approach I used), the model of which is shown on the third line of the display; on the fourth, it is possible to indicate a percentage uncertainty assessment to be applied to the reported price that can be entered by a “human” expert.
The response columns are as follows:
- Detection date
- Lower value of the acceptance interval of the day chosen by the user through the value of probability (90% in the model)
- The prediction made by the model
- Upper value of the acceptance interval of the day chosen by the user; obviously the value of column 2 and column 4 identify the acceptable price or not; outside the range, the forecast is incorrect
- Real price of the day
- Forecast error due to exit from the acceptance interval
- Forecast provided by the use of the trend model shown on the third row above
On line 6 you can see the indication of out range error (forecast 973.27; real minimum 971.42 i.e. an over estimation).
The data can be stored for subsequent evaluations, brought to Excel or shown.
Using the Show trend button, it is possible to view and graphically analyze the result of the forecast (both fuzzy and trend numerical value in the lower part, where the trend parameters are evaluated):
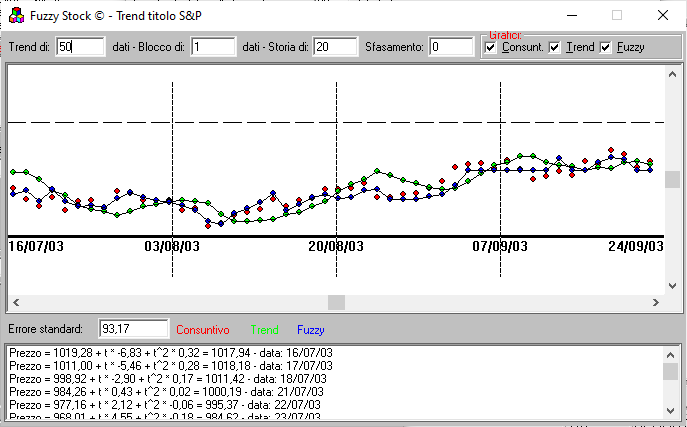
At the first line the number of last period observations; in red the price of the day; green forecasts for the trend; fuzzy ones in blue
The result of the fuzzy model is particularly interesting (obtainable by disabling the Trend flag) and using a larger series, in this case 50 items):
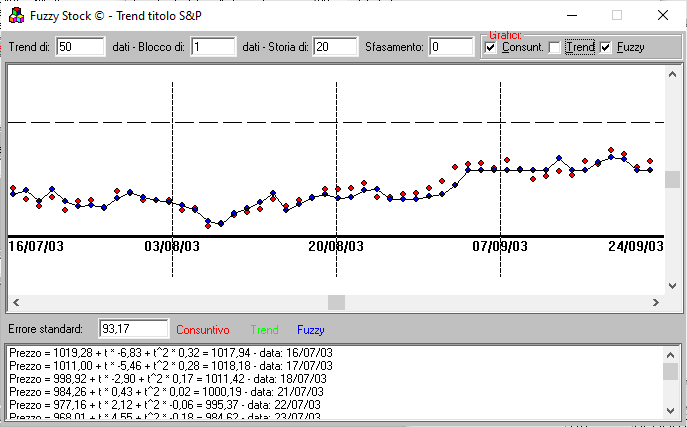
By eye it can be seen that the maximum forecast error occurred between 20/08 and 7/09; by clicking on the point, you get the detail of the observation:
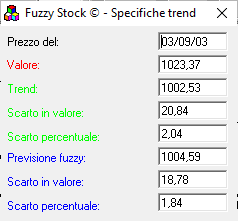
As you can see, the maximum error (Scarto percentuale) made by the fuzzy approach has a difference of less than 2% of the price.
Pleased, notice that this error was the biggest in the series, excluding a specific case I am going to point out .
It is interesting to note that a terrorist attack occurred in Madrid during the trial period.
Obviously, the result of this event has profoundly influenced the stock market price (and I suppose this was the reason for wrong forecasting).
Of course this event is known to operator, so the processing window had been modified adding the possibility for the human operator to insert his personal evaluation to the forecast, obviously dependent on the external events observed.

Leave a comment